
I- CONTEXTE ET OBJECTIF
Le principe de base des conteneurs est qu’ils sont conçus sans états, mais les données doivent tout de même être stockées et être accessibles à certains services. Vous avez donc besoin d’une solution qui préserve les données en cas de redémarrage de conteneurs.
Les demandes de volume persistant (Persistent Volume Claims ou PVC) sont les solutions recommandées pour la gestion d’applications à états dans Kubernetes.
Les systèmes de stockage distribués sont un moyen efficace de résoudre les ensembles à états hautement disponibles. Ceph est un système de stockage distribué qui, au cours des dernières années, a capté de plus en plus l’attention. Rook est un orchestrateur pour un ensemble divers de solutions de stockage, incluant Ceph. Rook simplifie le déploiement de Ceph dans un cluster Kubernetes.
Qu’est-ce que CEPH ?
CEPH est un système de stockage distribué extrêmement évolutif et hautement performant sans aucun point de défaillance.
Si vous voulez en savoir plus sur CEPH, nous vous proposons un article que nous avions déjà fait sur la mise en place d’un cluster ceph. (https://eazytraining.fr/informatique/devops/mise-en-place-dun-systeme-de-stockage-distribue-haute-disponibilite-cas-de-ceph-via-ansible/?doing_wp_cron=1605637044.8307890892028808593750)
Néanmoins nous allons brièvement proposer une architecture pour une synthèse du précédant article.
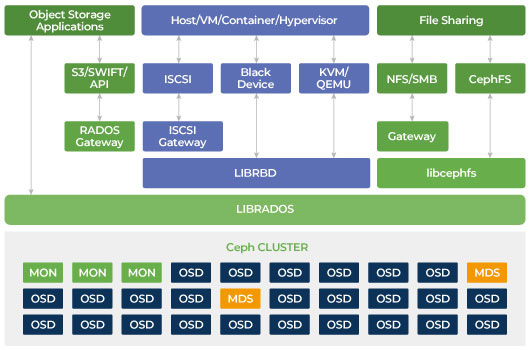
Dans cette architecture, Ceph nous montre qu’il est capable de proposer plusieurs interfaces de stockage (mode Bloc, Fichier et Objet).
Qu’est-ce que ROOK ?
Rook est un opérateur qui gère pour vous l’installation (Jour 1) et certaines tâches d’administration (jour 2) de CEPH qu’un administrateur du stockage devrait faire.
Rook déploie aussi des deamons de Ceph comme Pods dans Kubernetes.
Dans premier temps, nous allons déployer notre cluster kubernetes.
Dans un second temps intégrer Ceph à Kubernetes au travers de l’opérateur Rook
II- COMMENT DEPLOYER ROOK DANS KUBERNETES ?
Dans cet article, nous allons présenter les étapes à suivre pour déployer Rook dans un cluster Kubernetes. Comme Ceph exige de l’espace supplémentaire pour stocker les données, il est recommandé d’avoir un ensemble de disques supplémentaires réservés aux nœuds de stockage.
1- Environnement
Virtualbox :
3VMs,
8 Go RAM pour chaque VM (recommandé) mais vous pouvez utiliser 3Go RAM.
HDD 50 Go et 2 x 20 Go supplémentaires
OS : Ubuntu server 18.0.4 LTS
Service : Kubernetes (v1.18.0), docker, calico (CNI), ceph (CSI), rook, prometheus, grafana
Software : wordpress, mysql
ARCHITECTURE CIBLE
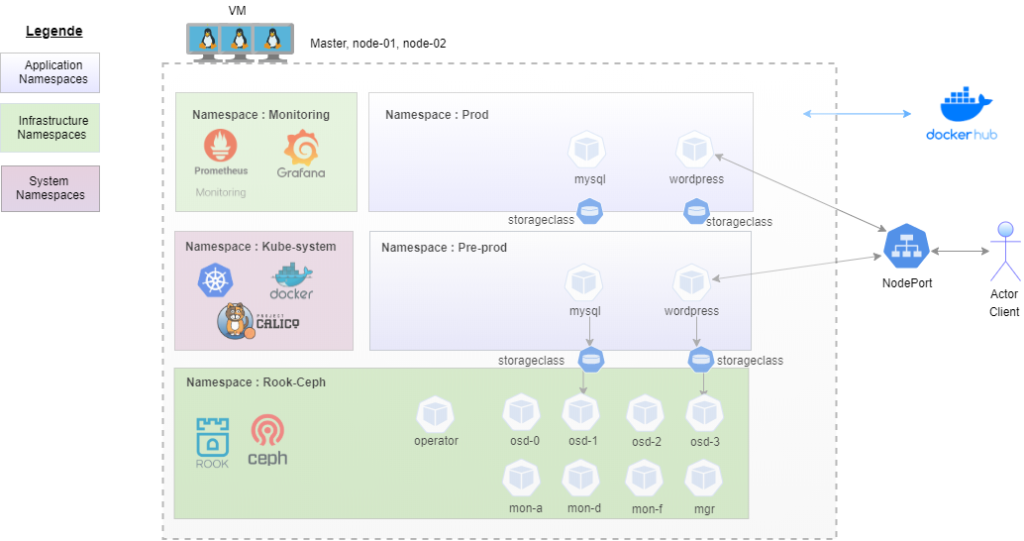
2- Déploiement de kubernetes
Nous allons déployer notre cluster kubernetes à l’aide de l’utilitaire « kubeadm ».
Networking address
172.16.16.0/24
Changer les noms de chaque node (master, node-01, node-02)
$ sudo hostnamectl
$ sudo hostnamectl set-hostname master (il faudra le faire pour les slaves)
root@ceph:~# vi /etc/hosts
172.16.16.4 master
172.16.16.5 node-01
172.16.16.6 node-02
Modifier les address ip
root@ceph:/opt/ceph-ansible# vi /etc/netplan/50-cloud-init.yaml
network:
ethernets:
enp0s3:
addresses: [172.16.16.4/24]
gateway4: 172.16.16.1
nameservers:
addresses: [172.16.16.1]
dhcp4: no
enp0s8:
dhcp4: no
version: 2
Faire communiquer les noeuds par SSH
root@master:~# ssh-keygen -t rsa
root@master:~# ssh-copy-id node-01
root@master:~# ssh-copy-id node-02
Test de communication des noeuds
root@master:~# ssh node-01
root@node-01:~# logout
Connection to node-01 closed
root@master:~# ssh node-02
root@node-02:~# logout
Connection to node-02 closed
Maintenant que l’environnement de travail est opérationnel, nous allons passer à l’installation proprement dit de kubernetes.
Allez dans la documentation de « kubernetes.io » et tapez « install kubeadm »
Il faudra désactiver le « swap » sur chaque noeud
root@master:~# swapoff -a
root@master:~# free -h
total used free shared buff/cache available
Mem: 1.9G 133M 1.4G 1.0M 408M 1.7G
Swap: 0B 0B 0B
Il faut permettre à « iptables » de voir le « bridge traffic » sur chaque nœud
root@master:~# sudo modprobe br_netfilter
root@master:~# lsmod | grep br_netfilter
br_netfilter 24576 0
bridge 151552 1 br_netfilter
root@master:~# cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
root@master:~# sudo sysctl –system
Il est important d’activer le firewall et établir les règles comme défini dans la documentation.
Etant donné que nous sommes en environnement de test, on va le désactiver pour les besoins fonctionnel afin qu’ils rejoignent notre cluster
root@master:~# ufw status
root@master:~# ufw disable
Installation d’un runtime de container (docker) sur chaque noeud
root@master:~# curl -fsSL https://get.docker.com -o get-docker.sh
root@master:~# sh get-docker.sh
Installation de « kubeadm » sur chaque noeud
root@master:~# sudo apt-get update && sudo apt-get install -y apt-transport-https curl
root@master:~# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add –
root@master:~# cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
root@master:~# sudo apt-get update
root@master:~# sudo apt-get install -y kubelet=1.18.0-00 kubeadm=1.18.0-00 kubectl=1.18.0-00
root@master:~# systemctl start kubelet
root@master:~# systemctl enable kubelet
root@master:~# systemctl status kubelet
Initialisation du cluster
Toujours dans la documentation « Using kubeadm to Create a Cluster »
On va initialiser le cluster
Attention!!! Attention!!! Cette commande doit être exécutée uniquement sur le noeud « master »

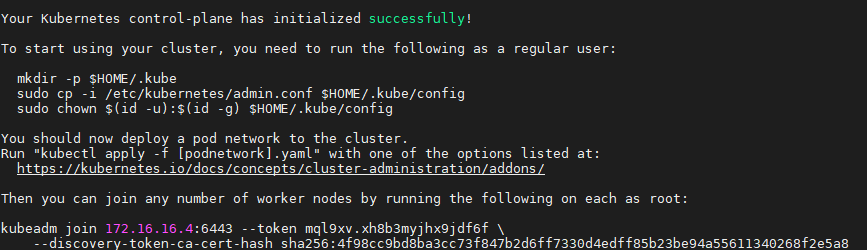
NB :
**Pour le 1er paramètre « –pod-network-cidr= » (il faut utiliser un subnet qui est différent du subnet de notre cluster. Ce subnet sera utilisé par les Pods donc il faut qu’il soit compatible avec le subnet du CNI [flannel, weave-net, calico] qu’on va choisir). Nous allons utiliser « CALICO » pour notre cas.
**pour le 2ème paramètre « –apiserver-advertise-address=ip-address » (ici il faut mettre l’@IP du controle plane qui est le « master » –> 172.16.16.4
root@master:~# exit
Nous quittons le compte root, pour donner les droits à notre user « devops » sur notre cluster kubernetes

Nous allons voir l’état de notre cluster kubernetes
devops@master:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady master 8m34s v1.18.0
On voit bien qu’il est en statut « NotReady » parce que notre CNI (Container Network Interface) n’est pas installé.
Avant ça donnons les droits sur le daemon docker à l’utilisateur « devops »
devops@master:~$ sudo usermod -aG docker devops
Installation du CNI (Calico)
On va faire une recherche sur google « install calico ».
Arrivez sur le site, choisissez « Self-managed on-premises » parce qu’on déploie en <<on-premises>>
devops@master:~$ kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
Jointure des « workers » au master
Au cas où vous oubliez de copier la commande de jointure (token)
devops@master:~$ kubeadm token create –print-join-command
kubeadm join 172.16.16.4:6443 –token 0njz1p.q3ezl8h36foml23y –discovery-token-ca-cert-hash sha256:4f98cc9bd8ba3cc73f847b2d6ff7330d4edff85b23be94a55611340268f2e5a8
Maintenant que la commande a été récupérée, vous pouvez exécuter cette commande sur chaque worker (‘node-01’ et ‘node-02’) pour qu’il rejoigne notre cluster.
**NODE-01
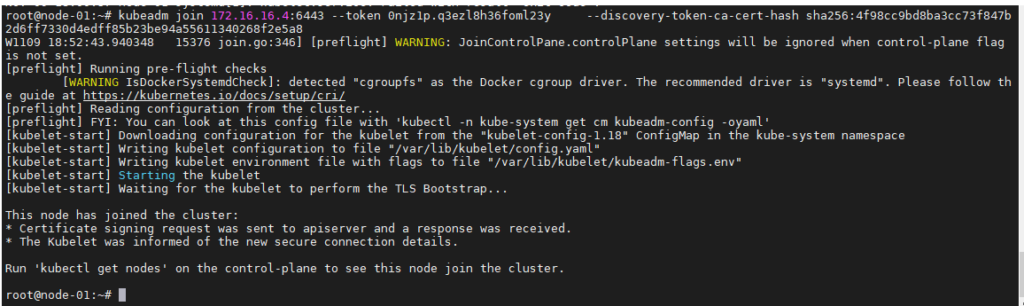
**NODE-02
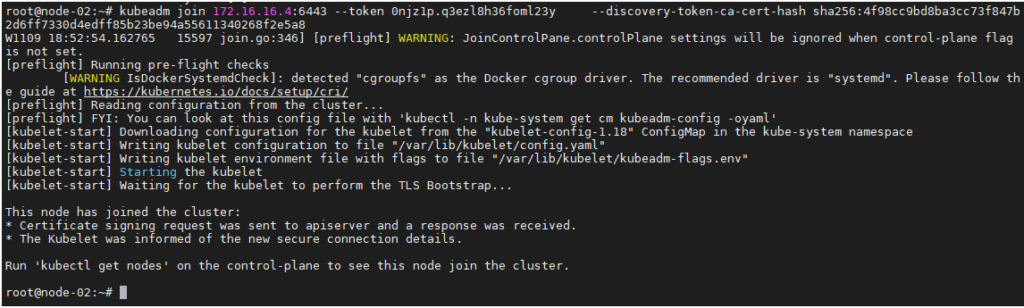
Nous allons vérifier l’état de notre cluster kubernetes à nouveau
devops@master:~$ kubectl get nodes
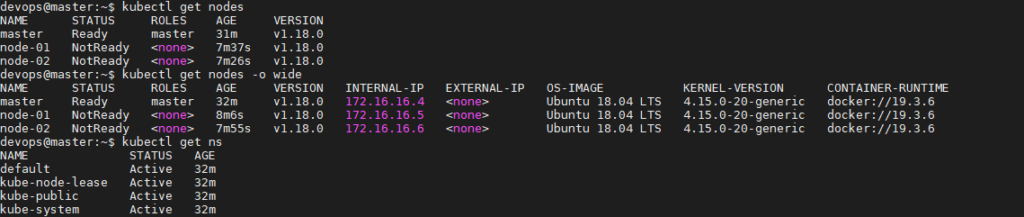
NB: Il faut patienter un tout petit peu afin que les différents workers soient « Ready » car Calico est entrain de configurer le « réseau » sur les « workers ».
Après avoir patienté, nous allons à nouveau refaire une vérification
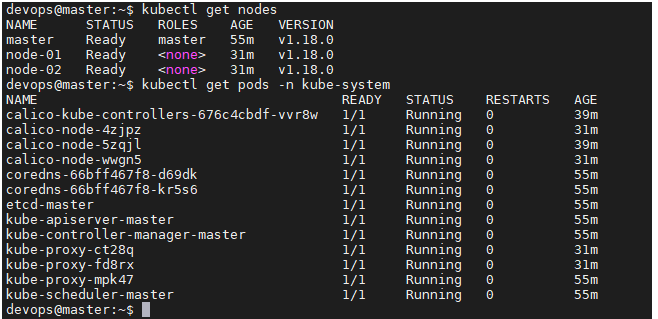
3- Déploiement de notre cluster rook-ceph
Nous allons récupérer le repository du projet rook sur github
devops@master:~$ git clone https://github.com/rook/rook.git
devops@master:~$ cd rook/cluster/examples/kubernetes/ceph/
Configuration de Ceph
Nous allons passer à la configuration de ceph avec les spécifications de la CSI (Container Storage Interface) en modifiant quelques fichiers pour l’adapter à notre environnement.
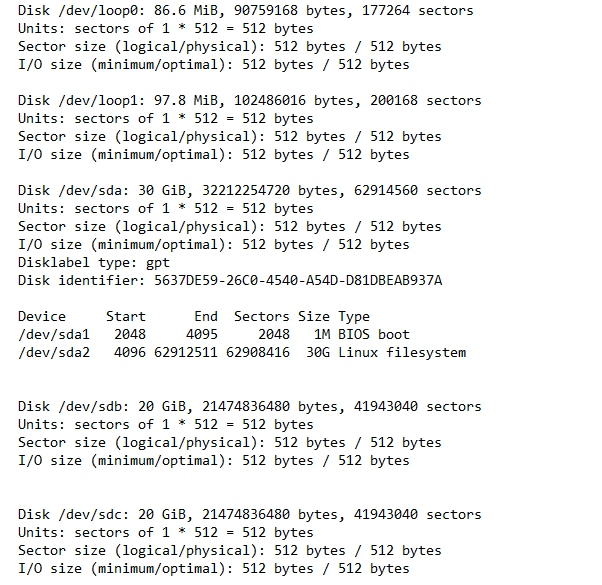
Vérifions l’état des disques sur chaque nœud et récupérer le nom des disques supplémentaires. Ces disques seront des daemons OSD pour CEPH.
devops@master:~/rook/cluster/examples/kubernetes/ceph$ sudo fdisk –l
Il faudra modifier le fichier « cluster.yml » . Vous trouverez le fichier dans le repository suivant: https://github.com/moussdia/k8s-rook-ceph.git
Néanmoins nous mettons la configuration utilisé dans ce fichier pour notre environnement

Déploiement de l’operateur Rook
Nous allons exécuter les commandes suivantes. Vous trouverez l’ensemble de fichier à exécuter dans le repository suivant https://github.com/moussdia/k8s-rook-ceph.git
devops@master:~/rook/cluster/examples/kubernetes/ceph$ kubectl create -f common.yaml
devops@master:~/rook/cluster/examples/kubernetes/ceph$ kubectl create -f operator.yaml
configmap/rook-ceph-operator-config created
deployment.apps/rook-ceph-operator created
Déploiement de cluster Ceph
Nous allons exécuter cette commande après avoir modifier le fichier « cluster.yml«
devops@master:~/rook/cluster/examples/kubernetes/ceph$ kubectl create -f cluster.yaml
cephcluster.ceph.rook.io/rook-ceph created
Création d’une classe de stockage (storageclass)
Nous allons créer une classe de storage qui va nous permettre de provisionner de manière dynamique notre Persistent Volume (PV)
devops@master:~/rook/cluster/examples/kubernetes/ceph$ cd /csi/rbd/
devops@master:~/rook/cluster/examples/kubernetes/ceph/csi/rbd$ kubectl apply –f storageclass.yaml
cephblockpool.ceph.rook.io/replicapool created
storageclass.storage.k8s.io/rook-ceph-block created
Installation du pod (outil) d’administration du cluster
Nous allons installer notre outil d’administration via lequel on pourra vérifier l’état de notre cluster CEPH. Il faut noter que l’opérateur Rook ne gère pas toutes les tâches d’administration
devops@master:~/rook/cluster/examples/kubernetes/ceph$ kubectl apply -f toolbox.yaml
deployment.apps/rook-ceph-tools created
Maintenant que tout est bon, essayons de vérifier l’état de « Rook » et de « Ceph »
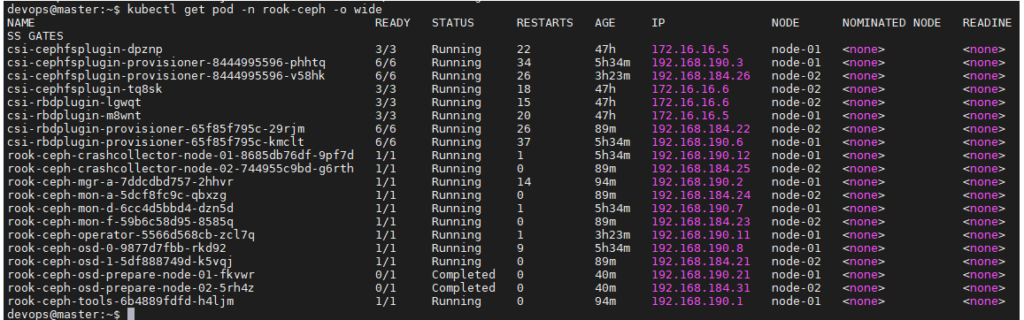
Nous allons entrer dans le pod d’administration (rook-ceph-tools-6b4889fdfd-59g26) du cluster pour vérifier si ceph s’est bien installé
devops@master:~$ kubectl -n rook-ceph exec –it rook-ceph-tools-6b4889fdfd-59g26 bash
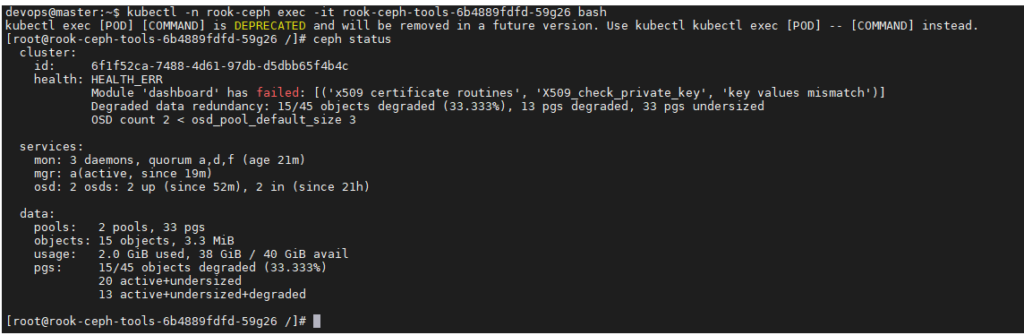
Nous allons créer notre Persistent Volume (PV) de manière dynamique en utilisant notre storageclass (rook-ceph-block) afin de fournir du volume aux différents Pods qu’on va créer par la suite.
Ceci dit, si nous voulons rendre les données de notre Pod persistantes, on devra obligatoirement utiliser cette approche
- A la création notre PVC (Persistent Volume Claim), déclarez notre storageclass qui permet de provisionner de manière dynamique notre PV
- Fournir ce PVC aux différents PODs, Deployments, Statefulset
Avec cette approche nous trouvons que c’est un choix judicieux de mettre notre base de données dans un cluster kubernetes puisque le CEPH garantie l’état de la donnée.
Exemple :
Essayons de créer un POD en utilisant un PVC
L’ensemble des fichiers de définition se trouve dans le repository suivant https://github.com/moussdia/k8s-rook-ceph.git
devops@master:~$ vi pvc.yaml
devops@master:~$ kubectl apply -f pvc.yaml
persistentvolumeclaim/rbd-pvc created
devops@master:~$ vi pod. yml
devops@master:~$ kubectl apply -f pod.yaml
pod/csirbd-demo-pod created
Vérifions l’état de notre POD, StorageClass, PVC, PV
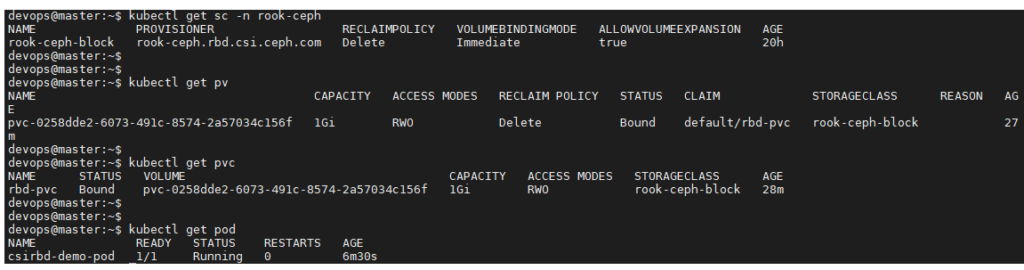
On voit bien que notre POD est « running« , ça veut dire qu’il utilise bien notre PVC et que le PV a été crée de manière dynamique à travers notre storageclass
CONCLUSION
Les PVC offrent l’avantage de séparer les Ops du Dev. Les administrateurs peuvent gérer l’état du cluster CEPH. Les développeurs peuvent faire une requête pour des volumes sans connaître les fournisseurs à l’arrière-plan.
Rook et Ceph peuvent aider les équipes à trouver des solutions pour le stockage.
Au regard de ce qui précède, nous venons de montrer l’intégration de rook-ceph dans un cluster kubernetes.
Dans le prochain article nous allons démontrer pourquoi les entreprises doivent mettre leur base de données dans kubernetes sans aucune crainte car le stockage c’est quelque chose de mature aujourd’hui dans kubernetes à travers Rook-Ceph.
Moussadia Soumahoro
Cloud & DevOps Engineer
https://www.linkedin.com/in/moussadia-soumahoro-555169152/