Construire une pipeline Data Engineering serverless et event-driven pour l’e-commerce avec AWS
Contexte et Problématique
Dans un contexte e-commerce moderne, les données de commandes sont générées en continu, souvent en temps réel, avec plusieurs contraintes fortes :- Volume variable et imprévisible (pics de ventes, promotions, Black Friday)
- Besoin d’historisation des données
- Découplage entre la génération des événements et leur exploitation analytique
- Accès simple via SQL pour les équipes métier ou data
- Coûts maîtrisés
Problème classique rencontré en entreprise :
“Nous avons des données de commandes, mais elles sont dispersées, difficiles à requêter, et chaque évolution du schéma casse les pipelines.” Les architectures traditionnelles ETL batch ne répondent plus à ces exigences. On a donc besoin d’une architecture data event-driven, scalable, serverless, et orientée analytics.2. La Solution : Architecture Event-Driven avec AWS Lambda
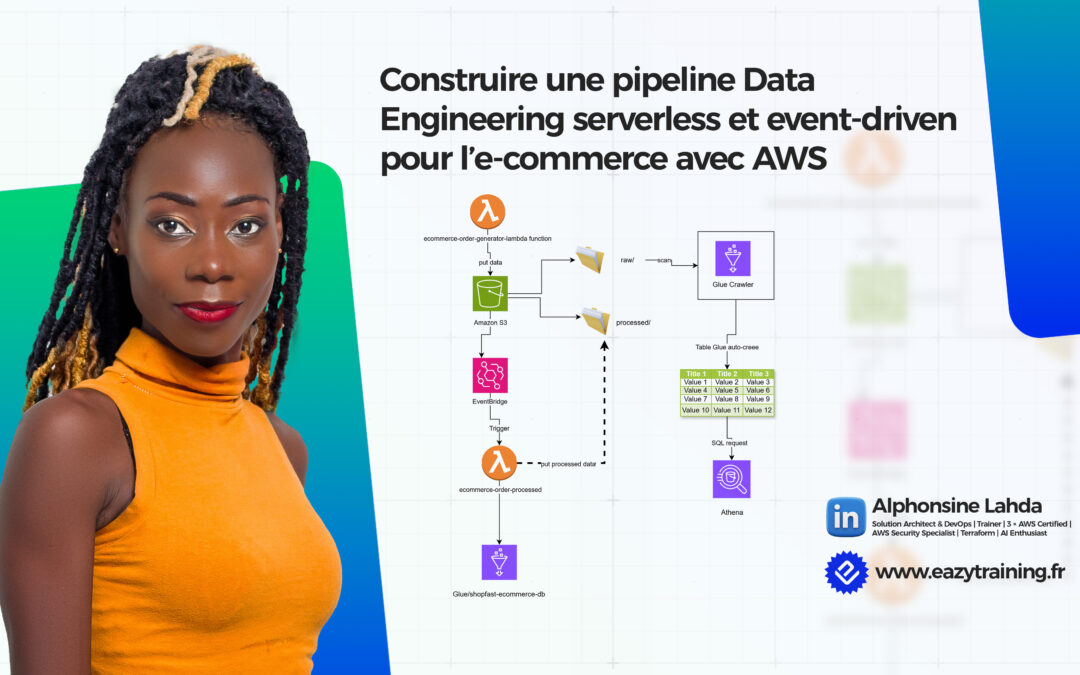
La solution proposée repose sur 5 principes clés : 1. Event-driven Chaque nouvelle commande est un événement, pas un batch. 2. Serverless-first Zéro serveur à gérer, montée en charge automatique. 3. Data Lake sur Amazon S3 Séparation claire entre données brutes et données transformées. 4. Catalogue de métadonnées automatique Grâce à AWS Glue Crawler. 5. Analyse SQL sans infrastructure Via Amazon Athena. Cette architecture permet : ● Une ingestion simple ● Une transformation asynchrone ● Une exploitation analytique immédiate Si vous souhaitez monter en compétence sur d’autres services AWS, spécialement serverless, l’article ci pourrait vous intéresser Application serverless.Architecture de solution

Caractéristiques Principales
● Serverless : Aucun serveur à gérer, scaling automatique ● Event-Driven : Architecture réactive basée sur les événements ● Cost-Optimized : Paiement à l’usage uniquement ● IaC avec CloudFormation : Infrastructure complètement automatisée ● Multi-environnement : Support dev, staging, production ● Monitoring : CloudWatch alarmes et logs intégrés ● Data Lake : Séparation raw/processed avec archivage automatique ● SQL Analytics : Requêtes SQL standard avec AthenaPrérequis
– Avoir un compte AWS ou en créer AWS account – Un compte AWS avec les droits administrateur.Implementation
Étape 1 : Création du bucket S3
1. Aller dans **S3 → Create bucket**. 2. Nommer le bucket `shopfast-ecommerce-data`. 3. Choisir la région souhaitée. 4. Décocher “Block all public access” si nécessaire pour tests internes. 5. Créer deux dossiers dans le bucket : `raw/` et `processed/`.
Créer 2 répertoires dans votre bucket S3, nous allons faire pareil pour notre cas, raw/ et
processed/ comme ceci:

Étape 2 : Création de la Lambda pour générer les commandes
1. Aller dans **Lambda → Create function → Author from scratch**.

2. Nom : `lambda_generate_orders`
3. Runtime : Python 3.14
4. IAM Rôle : celui créé avec accès S3 et CloudWatch
5. Coller le code Python `order-generator`
6. Configurer un test event minimal pour valider l’exécution.

Étape 3 : Création de la Lambda pour traiter les commandes
1. Aller dans **Lambda → Create function → Author from scratch**.
2. Nom : `lambda_process_orders`
3. Runtime : Python 3.14
4. IAM Role : accès S3 ReadWrite et CloudWatch
5. Coller le code Python `processed`
Étape 4 : Création d’une règle EventBridge
1. Aller dans **EventBridge → Rules → Create rule**


2. Nom : `trigger_process_lambda`

{
"source": ["aws.s3"],
"detail-type": ["Object Created"],"detail": {
"bucket": {
"name": ["shopfast-ecommerce-data"]
},
"object": {
"key": [{
"prefix": "raw/"
}]
}
}
}
6. Target : Lambda `lambda_process_orders`

7. Activez Input transformer : Et choisissez l'option input transformer
```json
{
"bucketName": "$.detail.bucket.name",
"objectKey": "$.detail.object.key"
}Au niveau de Template, collez ceci:
{
"Records": [{
"s3": {
"bucket": {
"name": "}
8. Sauvegarder la règle



Etape 5: Teste de la fonction lambda générateur de données:



Étape 6 : Création d’une base de données Glue
- Aller dans **AWS Glue → Databases → Add database**


- Nom : `ecommerce_shopclass_db`
- Description : Base pour projet workshop

- Nom : `ecommerce_shopclass_db`
- Description : Base pour projet workshop
Étape 6 : Création du Glue Crawler
- Aller dans **Glue → Crawlers → Add crawler**
- Set crawler en specifiant le Nom : `crawler_raw_orders`

3. Data source : S3 → pointer vers `s3://shopfast-ecommerce-data/raw/`


4. IAM Rôle : rôle avec permissions Glue et S3


- Schedule : On demand (manuelle)
- Output configuration: Base `ecommerce_shopclass_db`

-Review and create

7. Exécution du crawler pour créer la table automatiquement

- Patienter 1 à 2 minutes max pour se rassurer le crawler termine son exécution

- Teste pour voir si le crawler reellement creer la table de façon automatique
- Pour cela, se rendre sur Tables et voir si la table est présente:

- Ensuite, cliquer sur la table, pour voire elements ou “schema”

Étape 7 : Interrogation avec Athena
-
- Aller dans **Athena → Query editor**

Ensuite, cliquer sur “query”


- Sélectionner le bucket pour notre cas, c’est shopfast-ecommerce-data, ensuite spécifier le nom du répertoire dans lequel les résultats seront stockées, et ce répertoire sera créé de façon automatique par Athena

- Base : `ecommerce_shopclass_db`
- Exemples de requêtes :
- Vérification rapide des données
- Voir 10 lignes pour sanity check
SELECT *
FROM raw
LIMIT 10;
- Résultat:

- Compter le nombre total de commandes:
SELECT COUNT(*) AS total_orders
FROM raw;
- Analyse business de base
- Chiffre d’affaires total
SELECT
ROUND(SUM(subtotal + shipping_cost + (subtotal * tax_rate)), 2) AS total_revenue
FROM raw;

- Panier moyen:
SELECT
ROUND(AVG(subtotal), 2) AS avg_order_value
FROM raw;

- Répartition des commandes par ville:
SELECT
customer_city,
COUNT(*) AS orders_count,
ROUND(SUM(subtotal), 2) AS revenue
FROM raw
GROUP BY customer_city
ORDER BY revenue DESC;

- Travail sur la colonne ARRAY items (UNNEST)
Détail ligne par ligne des produits vendus
SELECT
r.order_id,
i.product_id,
i.product_name,
i.category,
i.quantity,
i.unit_price,
i.subtotal
FROM raw r
CROSS JOIN UNNEST(r.items) AS t(i);
- Top produits
SELECT
i.product_name,
SUM(i.quantity) AS total_quantity,
ROUND(SUM(i.subtotal), 2) AS revenue
FROM raw r
CROSS JOIN UNNEST(r.items) AS t(i)
GROUP BY i.product_name
ORDER BY revenue DESC
LIMIT 10;
- Top catégories
SELECT
i.category,
ROUND(SUM(i.subtotal), 2) AS revenue
FROM raw r
CROSS JOIN UNNEST(r.items) AS t(i)
GROUP BY i.category
ORDER BY revenue DESC;
- Le résultat de tous ses requêtes sur nos données sont disponible dans S3, précisément le répertoire athena-results/

- Analyse des remises
Commandes avec remise
SELECT
COUNT(*) AS discounted_orders
FROM raw
WHERE total_discount > 0;
Impact des remises par produit
SELECT
i.product_name,
ROUND(SUM(i.discount_amount), 2) AS total_discount_given
FROM raw r
CROSS JOIN UNNEST(r.items) AS t(i)
WHERE i.discount_percentage > 0
GROUP BY i.product_name
ORDER BY total_discount_given DESC;
- Requête prête pour dashboards (vue analytique)
SELECT
date(order_date) AS order_day,
customer_city,
COUNT(*) AS orders,
ROUND(SUM(subtotal), 2) AS revenue,
ROUND(AVG(subtotal), 2) AS avg_order_value
FROM raw
GROUP BY date(order_date), customer_city
ORDER BY order_day, revenue DESC;
Conclusion
Cette architecture représente une pipeline data moderne, pragmatique et efficace, parfaitement alignée avec les besoins e-commerce actuels. Son approche event-driven permet de traiter les données en temps réel, le serverless garantit scalabilité et maîtrise des coûts, et l’orientation analytics transforme les événements métiers en données immédiatement exploitables par les équipes.
Au-delà de l’aspect technique, cette solution est pensée pour la production. Elle est automatisable via l’IaC, évolutive sans refonte majeure, et constitue une base solide pour aller vers des usages plus avancés comme la gouvernance data, l’optimisation business ou l’intégration de l’IA. C’est une architecture qui accompagne la croissance, pas qui la freine.
Envie d’aller plus loin ?
Si vous souhaitez maîtriser ce type d’architecture de bout en bout, réservez un BootCamp AWS Cloud Engineer ou prenez un abonnement sur Eazytraining.
Vous y trouverez des formations pratiques, des cas réels et des architectures cloud prêtes pour la production.
Pour plus de contenus techniques, d’analyses cloud et de retours terrain, restez connectés aux prochains articles du blog.
Références
Auteur